Getting Started with Autoscaling Groups on AWS using Cloudformation


Autoscaling groups are a collection of EC2 instances which help you maintain desired instance count for your application. They help you scale up or down depending on traffic, but it also removes non-working instances if an issue arises and replaces it with a new one.
How does this all work? You basically specify a range to scale between (say minimum 2 and maximum 5 instances), and create cloudwatch metrics and alerts. For instance we will be using a CPUUtilization Target Tracking scaling policy which makes sure we are at around 60% CPU usage on our instances. If we dip down too low we scale down, if CPU usage increases we automatically scale up.
Setting this up takes a few different steps, hence I've opted to leave out the load balancing part for now. I will be putting out a part 2 of this article series which covers load balancing separately.
The different parts we require to set up an autoscaling group (ASG) are as follows:
a launchtemplate and security group
the autoscaling group itself
scaling policies to trigger scale up / down
Prerequisites
Before getting started, you will need the following prerequisites:
Creating the Launch template and Security group
At the start of the last couple articles we've always been creating EC2 instances which we've later been working with. This time we change it up slightly, and instead create a Launch template.
Like the name implies, it's simply a template for "launching" EC2 instances. So the setup is very similar to our normal EC2 setup. But it's a single configuration from which we can spin up multiple EC2 instances. To review the documentation check it out here.
# cfn.yml
Resources:
MyLaunchTemplate:
Type: AWS::EC2::LaunchTemplate
Properties:
LaunchTemplateName: MyLaunchTemplate
LaunchTemplateData:
SecurityGroups:
- !Ref InstanceSecurityGroup
KeyName: myKeyPair
ImageId: ami-0a261c0e5f51090b1
InstanceType: t2.micro
UserData:
Fn::Base64: !Sub |
#!/bin/sh
kill -9 $(cat /var/run/yum.pid)
yum update -y
yum install -y httpd
systemctl start httpd
systemctl enable httpd
echo "<h1>Hello World from $(hostname -f)</h1>" > /var/www/html/index.html
InstanceSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Enable SSH access via port 22 and http port 80
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 22
ToPort: 22
CidrIp: 0.0.0.0/0
- IpProtocol: tcp
FromPort: 80
ToPort: 80
CidrIp: 0.0.0.0/0Other than the Cloudformation type, everything is the same as when we are creating our normal EC2 instances. We're simply specifying security groups to use, userdata scripts to run, instance type, imageId and keypair to use.
Before creating the stack, remember to set up the keypair in case you don't have it from previous tutorials.
aws ec2 create-key-pair --key-name myKeyPair
# create myKeyPair.pem from output and chmod 0400 myKeyPair.pem
aws cloudformation create-stack \
--stack-name asg-getting-started \
--template-body file://cfn.ymlCreating the Autoscaling Group
Now we're already ready to create an autoscaling group. But let's start simple, without the scaling policies. This still has value since the ASG will make sure we always have our desired instance count running. We’ll see this shortly.
For this section we will be requiring three input parameters. One for our VPC and two for two public subnets where we want to deploy our ASG. When we create EC2 instances without specifying a VPC the instance is automatically created in our default VPC. For ASGs this is not the case, so we have to specify our default VPC explicitly.
Parameters:
MyVpc:
Description: A VPC available in your account
Type: AWS::EC2::VPC::Id
Default: "<your default VPC ID>"
PublicSubnetA:
Description: One of the public subnets
Type: AWS::EC2::Subnet::Id
Default: "<your first public subnet id>"
PublicSubnetB:
Description: Another public subnet
Type: AWS::EC2::Subnet::Id
Default: "<your other public subnet id>"You can find your default vpc id using the decribe-vpcs commands
aws ec2 describe-vpcs --filters Name=is-default,Values=trueA handy trick is to extract the value to an environment variable for easy reference later.
export VPC_ID=$(aws ec2 describe-vpcs \
--filters Name=is-default,Values=true \
| jq -r '.Vpcs[0].VpcId')
Now for the subnets we use the describe-subnets command
export SUBNET_A=$(aws ec2 describe-subnets \
--filters Name=vpc-id,Values=$VPC_ID \
| jq -r '.Subnets[0].SubnetId')
export SUBNET_B=$(aws ec2 describe-subnets \
--filters Name=vpc-id,Values=$VPC_ID \
| jq -r '.Subnets[1].SubnetId')Now we're ready to create our autoscaling group. Simply add the following at the bottom of cfn.yml.
# cfn.yml
AutoScalingGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
VPCZoneIdentifier:
- !Ref PublicSubnetA
- !Ref PublicSubnetB
LaunchTemplate:
LaunchTemplateId: !Ref MyLaunchTemplate
Version: !GetAtt MyLaunchTemplate.LatestVersionNumber
MinSize: '2'
MaxSize: '3'
HealthCheckGracePeriod: 60We specify that we want at least two instances to always be running, but we allow scaling up to three instances. We also specify the launchtemplate to use, and the subnets to launch the instances into.
The HealthCheckGracePeriod is to give the instance time to start up before health checks start being fired against it. Without this an instance might be taken out of service again before it is even up and running.
At this point we actually need one final modification. In your security group, add a reference to the VPC like this
# cfn.yml
InstanceSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Enable SSH access via port 22 and http port 80
VpcId: !Ref MyVpc # <--- ADD THIS
SecurityGroupIngress:
...and also update the reference to it in the Launchtemplate
MyLaunchTemplate:
Type: AWS::EC2::LaunchTemplate
Properties:
LaunchTemplateName: MyLaunchTemplate
LaunchTemplateData:
SecurityGroupIds: # <-- CHANGE THIS
- !Ref InstanceSecurityGroupThis is because we are now explicitly providing the VPC through the ASG, and then we have to do it here as well for it to work. I personally found this quite confusing, but the documentation explains it quite clearly
For a nondefault VPC, you must use security group IDs instead.
Ok great, now we're finally ready. Update the stack and in a minute or two you should see that two EC2 instances are running.
aws cloudformation update-stack \
--stack-name asg-getting-started \
--template-body file://cfn.yml --parameters \
ParameterKey=MyVpc,ParameterValue=$VPC_ID \
ParameterKey=PublicSubnetA,ParameterValue=$SUBNET_A \
ParameterKey=PublicSubnetB,ParameterValue=$SUBNET_B Check the public IPs in the stack and curl the instances to make sure everything works.
aws cloudformation describe-stacks --stack-name asg-getting-started \
--query "Stacks[0].Outputs"Now you can check out the ASG in the UI.
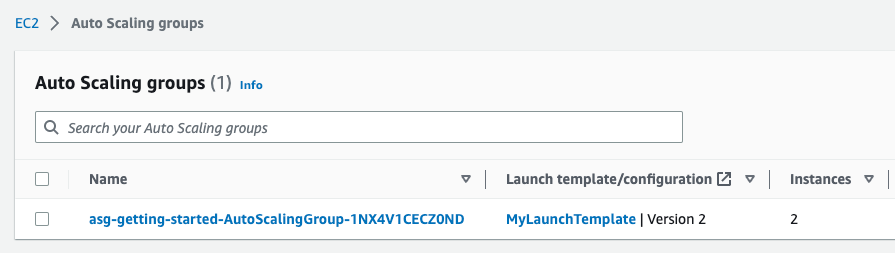
And under “Activity history” we see that two events were created because there was a difference between the desired and actual states.

You can also of course inspect the autoscaling group using the CLI if you prefer
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups \
| jq -r '.AutoScalingGroups[0].AutoScalingGroupName')
aws autoscaling describe-scaling-activities \
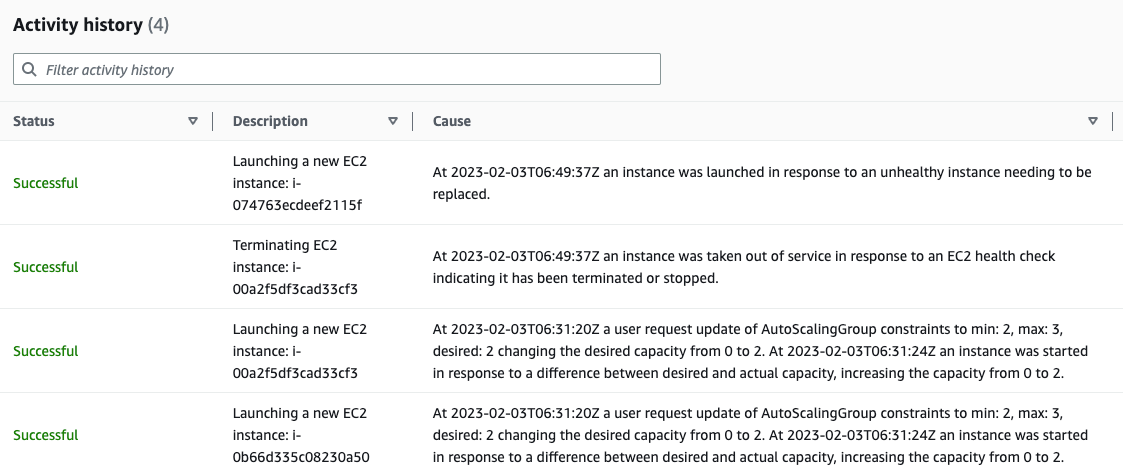
--auto-scaling-group-name $ASG_NAMENow we can try terminating an instance and see how the ASG reacts. Grab an instance id from the above describe-auto-scaling-groups command and terminate the instance
aws ec2 terminate-instances --instance-ids <instance id>After a moment we see that an instance is starting up. Remember that we now have to wait the HealthCheckGracePeriod before the instance starts receiving health checks and can be accepted as healthy by the ASG.
After the HealthCheckGracePeriod is over we see that the instance spun up successfully.
Scaling Policies
Scaling policies are a core part to setting up autoscaling for EC2. Using the autoscaling group up until now we’ve managed to have AWS maintain a set amount of instances for us, but there is no scaling up or down based on traffic like one would want from an autoscaling setup.
There are various types of scaling policies.
Target Tracking
Simple and Step Scaling
Scheduled Actions
Predictive Scaling
Target Tracking
The simplest and most straight forward way to manage the scaling of your application is using a Target Tracking scaling policy. You simply choose a metric and a target value and AWS will create Cloudwatch alarms for you to scale up and down when the metric is deviated from.
In our case we will be using Target Tracking scaling with the CPUUtilization metric. But note that there are other metrics that might be a better choice for your application, like RequestCountPerTarget for example.
Simple and Step Scaling
While Target Tracking scaling policies remove a lot of the complexity for you, Simple and Step scaling policies allow you to adjust your scaling policies in more detail. You get to create your alarms yourself, and set when they should be triggered and how many instances should be added or removed.
The simple scaling policy waits for health checks to be passing on newly created instances before triggering new scaling actions. Step scaling however allows for even more scaling actions while one is undergoing.
Scheduled Actions
Scheduled scaling is really handy for big events. Do you expect more traffic on black Friday perhaps, or is there some larger event coming up which will attract more customers? For these type of known high-traffic events scheduled actions are perfect.
Simply specify a date and time to change the minimum, maximum and desired counts for your autoscaling group, and the policy will take care of the rest.
Predictive Scaling
Predictive Scaling is very interesting, it uses machine learning to analyze past traffic trends and could be a great fit if you have predictable scaling needs. For instance if you always have more traffic in the evening and very little during the day, predictive scaling can help you to scale up before the metrics start showing an issue.
Creating a Scaling Policy
Ok, that’s enough theory. Let’s create our scaling policy using cloudformation.
# cfn.yml
ScalingPolicy:
Type: AWS::AutoScaling::ScalingPolicy
Properties:
AutoScalingGroupName: !Ref AutoScalingGroup
PolicyType: TargetTrackingScaling
TargetTrackingConfiguration:
PredefinedMetricSpecification:
PredefinedMetricType: ASGAverageCPUUtilization
TargetValue: 60We specify the policy type of TargetTrackingScaling and the PredifinedMetricType of ASGAverageCPUUtilization with a TargetValue of 60%. Note how simple this is since we don’t have to create the metric (since it is predefined) and we also don’t even have to create the alarms since we’re using Target Tracking.
After updating the stack we can filter our Cloudwatch alarms by prefix to see the ones we’ve created through our scaling policy.
aws cloudwatch describe-alarms \
--alarm-name-prefix TargetTracking-asg-getting-started
aws application-autoscaling describe-scaling-policiesNow we’re ready to test it out. Let’s scale down to a single EC2 instance to make the testing easier. Update the ASG in cloudformation and run the update-stack command from above again.
# cfn.yml
MinSize: '1' # <-- CHANGE THIS
MaxSize: '3'
HealthCheckGracePeriod: 60And now we ssh onto the remaining EC2 instance and stress the CPU using the appropriately named stress command.
sudo amazon-linux-extras install epel -y
sudo yum install stress -y
stress -c 4We wait a couple of minutes and see that a new instances starts spinning up because the “AlarmHigh” alarm was triggered.

And after a minute or two the health checks are passing and the EC2 has successfully been added to our ASG.
